Update [2024.12.7]:增加条件生成以及潜在扩散模型的介绍。
Update [2024.12.11]:增加评估指标的对比以及超参数调整。
Update [2024.12.12]:增加对于扩散模型个性化生成微调方法的介绍
生成模型
目前主流的生成模型包括生成对抗模型 (GAN)、变分自编码器 (VAE)和基于流的模型 (Flow-based models)。
它们都能够生成较高质量的图像,但是也都具有一定的局限性。由于GAN模型具有对抗性训练的性质,因此其训练过程比较脆弱且难以稳定收敛,生成图像的多样性也较低。与GAN相比,VAE经常会生成较模糊、不够锐利的样本,因为VAE在优化过程中引入了KL散度正则项,鼓励潜变量分布与先验分布靠拢,因此会损失部分细节信息。基于流的生成模型通过严格的可逆变换实现对数据分布的精确密度估计,这意味着每一步变换需要是可逆且雅可比行列式可计算,因此在模型设计上对层结构有较强限制。
扩散模型的设计思路来自非平衡热力学。模型定义了一个马尔可夫扩散步骤,缓慢地向图像中添加随机噪声,然后学习扩散的逆过程以从噪声中构建所需要的数据样本。

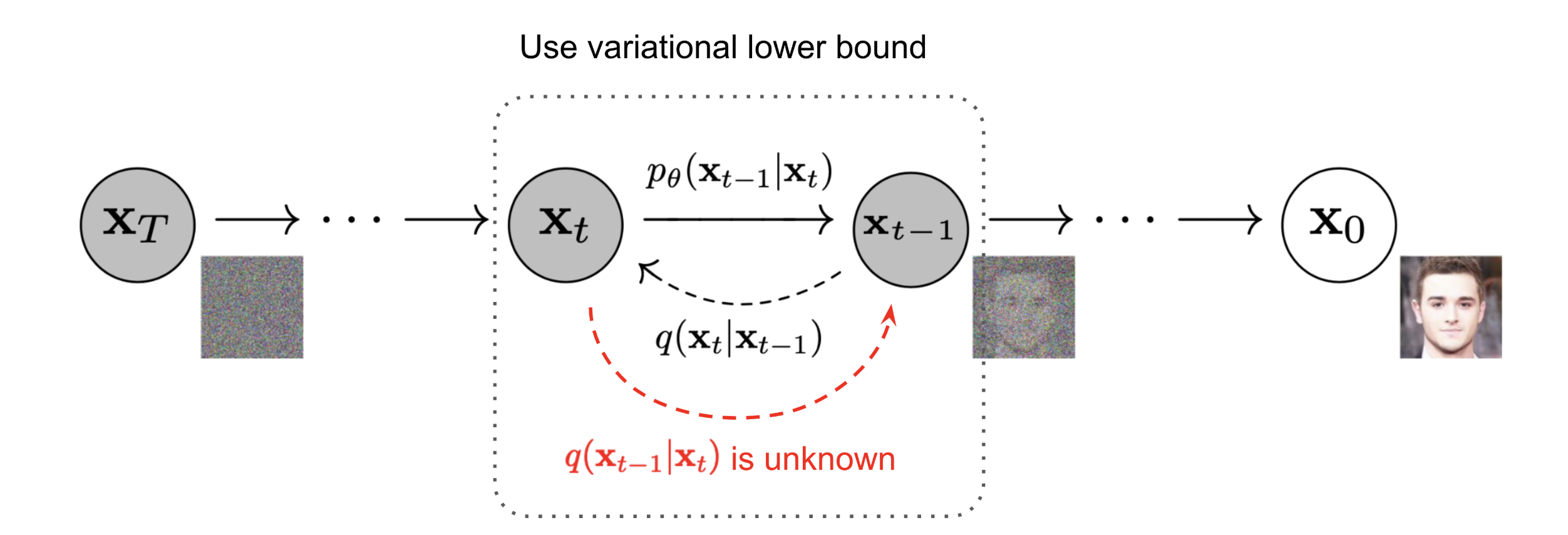
什么是扩散模型?
目前主流的基于扩散的生成模型包括扩散概率模型 (Diffusion Probabilistic Models)、条件噪声打分网络 (noise-conditioned score network)和去噪扩散概率模型 (denoising diffusion probabilistic models, DDPM),扩散过程包括前向扩散过程和逆向扩散过程。
前向扩散过程
给定从真实数据分布中采样的数据点 $x_0$ ~ $q(x) $ ,定义一个前向扩散过程,在这个过程中,我们向样本中添加高斯噪声 $T$ 步,产生一系列含有噪声的样本 $ x_1, …, x_T $。 $$ q(x_t|x_{t-1})=\mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1},\beta_tI) \ q(x_{1:T}|x_0) = \prod_{t=1}^Tq(x_t|x_{t-1}) $$ 随着加噪步数的增加,图像特征逐渐消失,最终当T趋近于无穷时,$x_T$ 相当于各向同性的高斯分布。
上述采样过程能够使我们计算出在时间t时刻的采样$x_t$。令
逆向扩散过程
为了实现从无序噪声恢复到数据分布(即反向扩散过程),需要对后验分布 $q(x_{t-1}|x_t, x_0)$ 进行分析。根据贝叶斯公式:
可以得到忽略加权项的简化目标来训练扩散模型,最终设计的损失函数如下:

实现一个DDPM
为了更清楚地了解扩散模型的整体架构,而不是为了探究复杂的概率论和数学原理,使用diffusers库实现DDPM的训练和推理。

我们使用huggingface上的huggan/smithsonian_butterflies_subset作为训练数据集,该数据集包含自然界各种各样的蝴蝶,可用于无条件的图像生成过程。
参数配置
首先按照以下配置进行训练和推理步骤的参数配置:
from dataclasses import dataclass
@dataclass
class TrainingConfig:
image_size = 128
train_batch_size = 32
eval_batch_size = 8 # how many images to sample during evaluation
num_epochs = 50
gradient_accumulation_steps = 1
learning_rate = 1e-4
lr_warmup_steps = 500
save_image_epochs = 10
save_model_epochs = 25
mixed_precision = "fp16" # `no` for float32, `fp16` for automatic mixed precision
output_dir = "output" # the model name locally and on the HF Hub
seed = 42
device = "cuda"
config = TrainingConfig()
训练数据准备
然后使用huggingface的datasets库进行数据集的下载和导入:
from datasets import load_dataset
config.dataset_name = "huggan/smithsonian_butterflies_subset"
dataset = load_dataset(config.dataset_name, split="train")
使用以下代码查看数据集中的图像:
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 4, figsize=(16, 4))
for i, image in enumerate(dataset[:4]["image"]):
axs[i].imshow(image)
axs[i].set_axis_off()
fig.show()

使用torchvision库中的transforms模块,将图像的尺寸和数值归一化处理:
from torchvision import transforms
preprocess = transforms.Compose([
transforms.Resize((config.image_size, config.image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
])
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"img": images}
dataset.set_transform(transform)
print(dataset[0]['img'].shape)
# torch.Size([3, 128, 128])
定义一个dataloader用于数据集的批量加载:
import torch
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=config.train_batch_size, shuffle=True)
使用U-Net进行噪声预测
在扩散模型中,可以使用MLP或者U-Net来进行噪声的预测,从而将噪声一步一步去噪得到真实图像。选择U-Net作为噪声预测的模型,U-Net的架构由下采样堆栈和上采样堆栈构成。
- 下采样:每个步骤包括重复应用两个 3x3 卷积(无填充卷积),每个卷积后跟一个 ReLU 和一个步幅为 2 的 2x2 最大池化。在每个下采样步骤中,特征通道的数量都会加倍。
- 上采样:每个步骤包括对特征图的上采样,然后进行 2x2 卷积,并且每次将特征通道数量减半。
- 捷径连接:上下采样堆栈相应层通过捷径连接,为上采样过程提供必要的高分辨率特征。
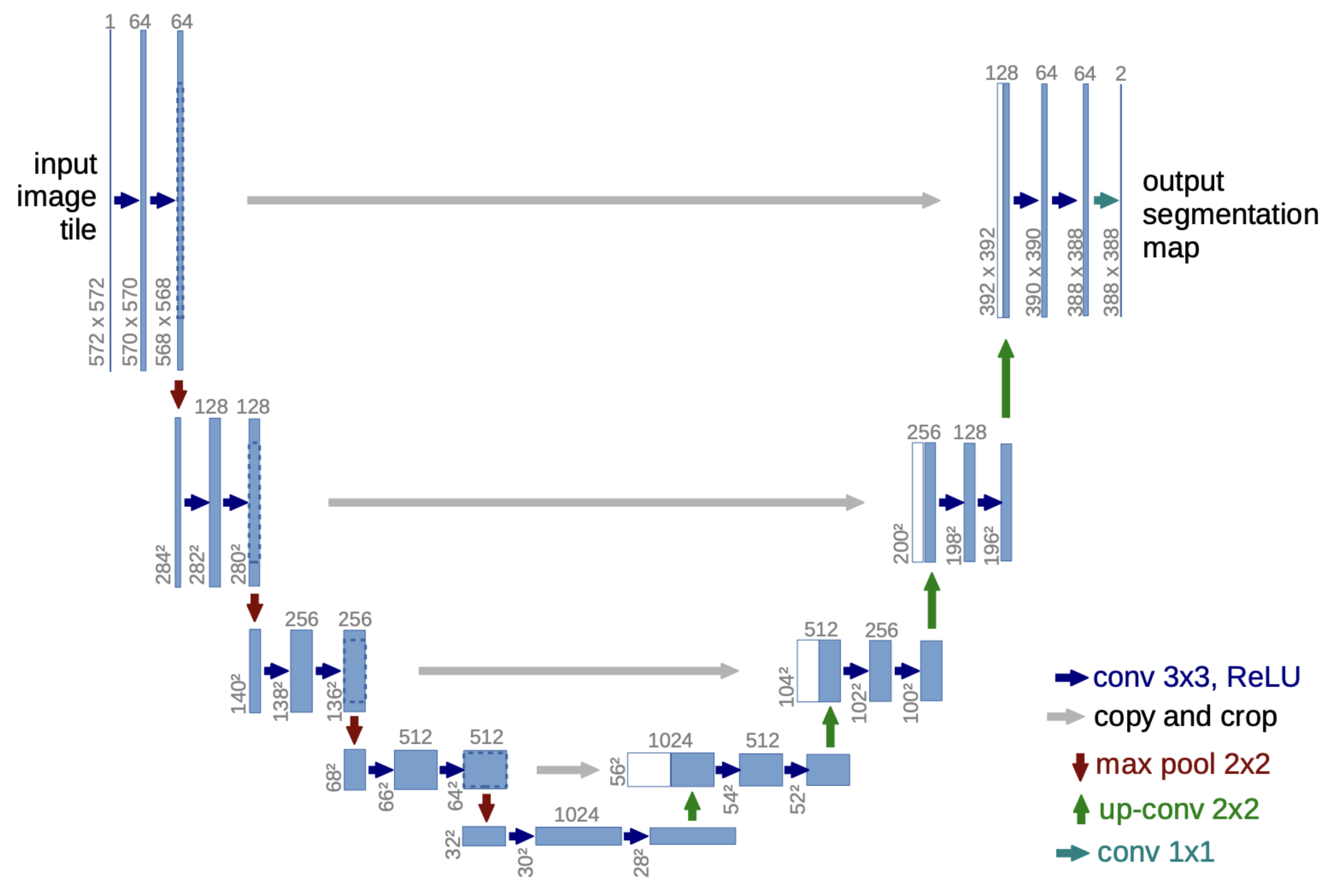
实现如下:
from diffusers import UNet2DModel
model = UNet2DModel(
sample_size=config.image_size, # the target image resolution
in_channels=3, # the number of input channels, 3 for RGB images
out_channels=3, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(128, 128, 256, 256, 512, 512), # the number of output channels for each UNet block
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"DownBlock2D",
),
up_block_types=(
"UpBlock2D", # a regular ResNet upsampling block
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
),
)
# Check input and output shapes
sample_image = dataset[0]['img'].unsqueeze(0)
print("Input Shape", sample_image.shape)
print("Output Shape", model(sample_image, timestep=0).sample.shape)
通过检查输入U-Net和输出U-Net的图像形状,可以得知输入和预测噪声的形状一致,满足扩散模型的需求。
DDPM Scheduler
创建一个噪声调度器,用来在不同的时间步中为图像加噪。
# Create a DDPM scheduler
import torch
from PIL import Image
from diffusers import DDPMScheduler
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
noise = torch.randn(sample_image.shape)
timesteps = torch.LongTensor([50])
noisy_image = noise_scheduler.add_noise(sample_image, noise, timesteps)
Image.fromarray(((noisy_image.permute(0,2,3,1)+1.0)*127.5).type(torch.uint8).numpy()[0])
从加噪后的输出可以看出,图像中出现了明显的噪声。

创建优化器和学习率调度器
# Create optim and lr scheduler
from diffusers.optimization import get_cosine_schedule_with_warmup
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=config.lr_warmup_steps,
num_training_steps= (len(train_dataloader)*config.num_epochs)
)
设计损失函数
扩散模型的核心在于优化预测噪声的模型,因此需要使预测噪声的模型 (U-Net) 输出的噪声与实际噪声的分布接近。因此损失函数可以简单地设计为:
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
loss = F.mse_loss(noise_pred, noise)
训练过程
使用huggingface的accelerate库进行方便的模型加载、权重保存以及模型评估。训练的整体思路是生成图像不同时间步中加入噪声后的图像,U-Net接受加噪后的图像以及其对应的时间步,预测出该步骤加入的噪声。预测噪声与实际加入的噪声使用loss进行计算,最小化loss,进而使U-Net具有预测噪声的能力。最终在推理过程中能够使用U-Net在每个时间步进行去噪,最后生成接近真实分布的图像。训练循环代码如下:
from accelerate import Accelerator
from tqdm.auto import tqdm
from pathlib import Path
import torch.nn.functional as F
import os
def train_loop(config, model, noise_scheduler, optimizer, train_dataloader, lr_scheduler):
# Initialize accelerator
accelerator = Accelerator(
mixed_precision=config.mixed_precision,
gradient_accumulation_steps=config.gradient_accumulation_steps,
project_dir=os.path.join(config.output_dir, "logs")
)
if accelerator.is_main_process:
if config.output_dir is not None:
os.makedirs(config.output_dir, exist_ok=True)
# Prepare everything
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, lr_scheduler
)
global_step = 0
# Train!
for epoch in range(config.num_epochs):
progress_bar = tqdm(total=len(train_dataloader), disable=not accelerator.is_local_main_process)
progress_bar.set_description(f"Epoch {epoch}")
for step, batch in enumerate(train_dataloader):
clean_images = batch["img"]
# Sample noise to add to the clean image
noise = torch.randn(clean_images.shape, device=config.device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bs,), device=config.device, dtype=torch.int64
)
# forward diffusion process
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
with accelerator.accumulate(model):
# Predict Noise residual
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
loss = F.mse_loss(noise_pred, noise)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(model.parameters(), 1.0) # Gradient clipping
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
global_step += 1
# Evaluation
if accelerator.is_main_process:
pipeline = DDPMPipeline(unet=accelerator.unwrap_model(model), scheduler=noise_scheduler)
if (epoch + 1) % config.save_image_epochs == 0:
evaluate(config, epoch, pipeline)
if (epoch + 1) % config.save_model_epochs == 0:
pipeline.save_pretrained(os.path.join(config.output_dir, f"epoch_{epoch}"))
elif (epoch + 1) == config.num_epochs:
pipeline.save_pretrained(os.path.join(config.output_dir, f"final"))
其中,模型评估的代码如下:
# Evaluation
from diffusers import DDPMPipeline
from diffusers.utils import make_image_grid
import os
def evaluate(config, epoch, pipeline):
images = pipeline(
batch_size = config.eval_batch_size,
generator = torch.Generator(device=config.device).manual_seed(config.seed),
).images
image_grid = make_image_grid(images, rows=2, cols=4)
test_dir = os.path.join(config.output_dir, "test")
os.makedirs(test_dir, exist_ok=True)
image_grid.save(os.path.join(test_dir, f"epoch_{epoch}.png"))
训练与推理结果
最后使用以下代码在Jupyter Notebook中启动训练:
rom accelerate import notebook_launcher
args = (config, model, noise_scheduler, optimizer, train_dataloader, lr_scheduler)
notebook_launcher(train_loop, args, num_processes=1)
最终不同训练epoch的推理结果如下:
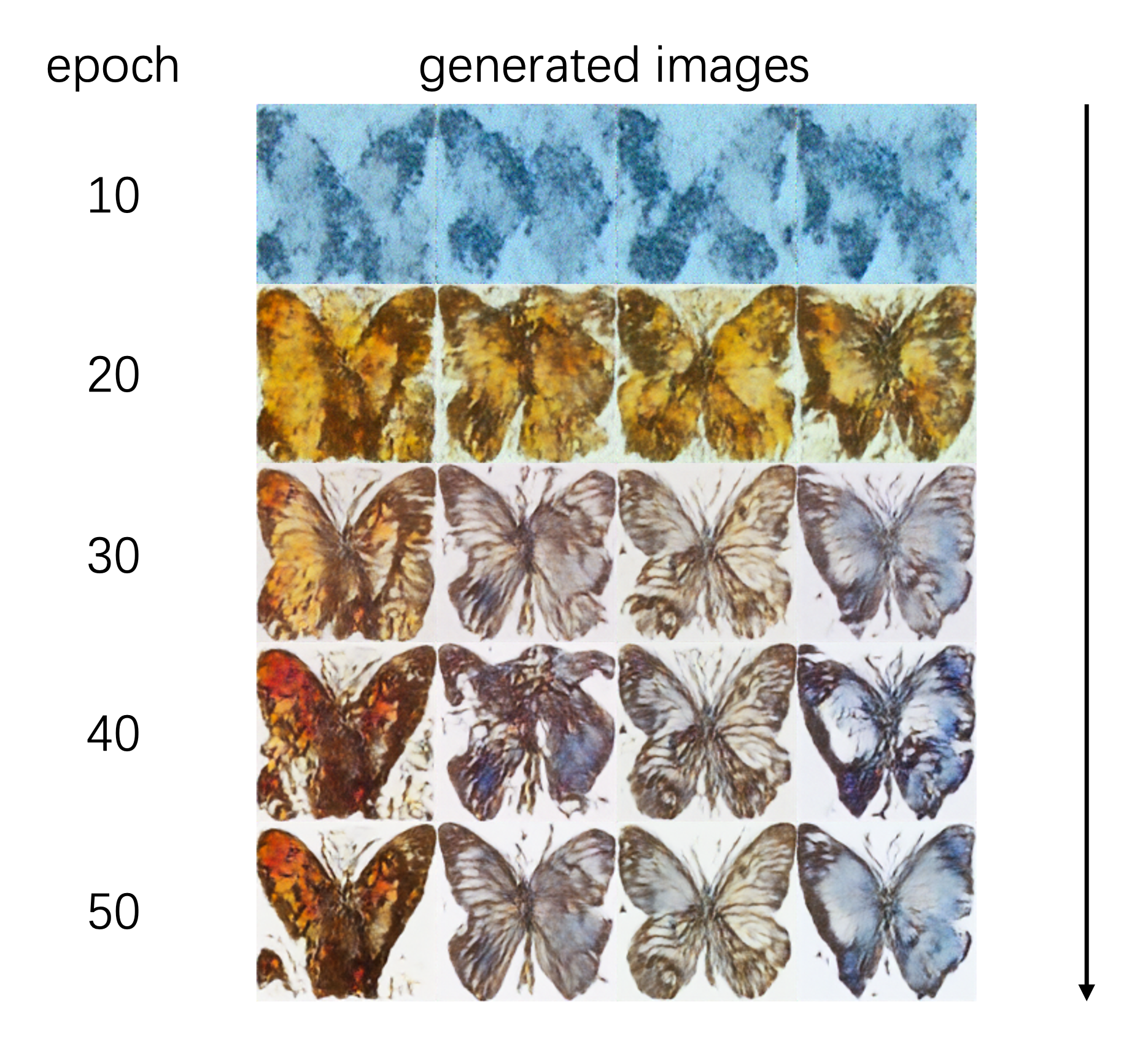
可以看出,随着训练步数的增加,生成的图像越来越向真实的图像分布(蝴蝶形态)靠拢,说明经过训练后,扩散模型具有了生成图像的能力。
使用IS和FID指标进行图像质量评估
什么是IS (Inception Score) ?
Inception Score 是一种对生成图像的质量和多样性进行评价的指标。其思路是利用一个预训练好的分类模型(通常是 Inception v3)对生成的图像进行分类,然后根据分类结果的分布来计算得分。
$p(y|x)$ 为给定生成图像 $x$ 的类别分布,$p(y) = \int p(y|x) p(x) dx$ 为所有生成图像的平均类别分布,$KL(\cdot|\cdot)$ 为KL散度,则IS为: $$ \text{IS} = \exp\left( \mathbb{E}_{x}\bigl[ KL(p(y \mid x) | p(y)) \bigr] \right) $$
直观上:
- 如果生成图像的质量高,则概率分布应该集中在某些明确的类上(即分布峰值较高,说明图像能够被轻松分类)
- 如果生成图像的多样性高,则概率分布应该均匀覆盖多个类别。
综合来看,IS高时,说明生成图像既清晰又多样。
什么是FID (Frechet Inception Distance) ?
FID 用于衡量生成分布和真实数据分布在特征空间(通常是 Inception v3 的中间特征层)上的差异。与IS不同,FID需要真实样本和生成样本作为对比,关注两者之间的统计差异。
设真实数据特征分布为 $\mathcal{N}(\mu_r, \Sigma_r)$,生成数据特征分布为 $\mathcal{N}(\mu_g, \Sigma_g)$,则FID定义为两高斯分布的Fréchet距离: $$ \text{FID}(\mu_r, \Sigma_r, \mu_g, \Sigma_g) = |\mu_r - \mu_g|^2 + \text{Tr}\left(\Sigma_r + \Sigma_g - 2(\Sigma_r \Sigma_g)^{1/2}\right). $$ 其中,$\mu_r, \Sigma_r$ 为真实分布特征的均值和协方差,$\mu_g, \Sigma_g$ 为生成分布特征的均值和协方差,$\text{Tr}(\cdot)$ 为迹运算,$( \Sigma_r \Sigma_g )^{1/2}$ 为矩阵的对称正定平方根。
直观上:
-
FID衡量的是两个高斯分布之间的Fréchet距离,当两组特征分布一致时,FID为0(理想情况下)。
-
如果生成图像质量越高越逼近真实分布,那么 $\mu_g \approx \mu_r$ 且 $\Sigma_g \approx \Sigma_r$,因此FID会很低。
-
如果生成图像与真实分布偏差大,分布统计差异明显,FID会较高。
IS与FID的对比
| 指标 | IS(Inception Score) | FID(Fréchet Inception Distance) |
|---|---|---|
| 目标 | 测量生成图像的多样性和清晰度 | 测量生成图像与真实图像分布的相似性 |
| 公式 | 基于分类分布的KL散度 | 高斯分布均值和协方差的Fréchet距离 |
| 数值范围 | 无上限 | 0 (越低越好) |
| 优点 | 简单直观,关注多样性和清晰度 | 综合考虑细节和分布相似性 |
| 缺点 | 不考虑生成图像与真实图像的匹配程度 | 计算依赖样本量,复杂度稍高 |
| 适用场景 | 快速评估生成图像的基本性能 | 更全面的衡量生成图像质量和真实感 |
IS评估
测量IS和FID指标,需要的图像数量至少需要上万张,由于生图速度较慢,使用500张生成图像进行IS指标的测量。
首先使用以下代码进行sampling:
# Generate samples
from diffusers import DDPMPipeline
import random
pipeline = DDPMPipeline.from_pretrained("/openbayes/home/miyan/works/Diffusion-Model-0-1/output/epoch_49").to(config.device)
samples_num = 500
batch_size = 20
for epoch in range(samples_num // batch_size):
images = pipeline(
batch_size = batch_size,
generator = [torch.Generator(device=config.device).manual_seed(random.randint(0, 100000)) for _ in range(batch_size)],
).images
test_dir = os.path.join(config.output_dir, "samples")
os.makedirs(test_dir, exist_ok=True)
for i, image in enumerate(images):
image.save(os.path.join(test_dir, f"{i+epoch*batch_size}.png"))
使用以下代码进行IS指标的测量:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import numpy as np
from scipy.linalg import sqrtm
def calculate_inception_score(images, device, batch_size=32, splits=10):
"""
计算 Inception Score (IS)。
参数:
images: torch.Tensor,形状为(N, C, H, W) 的生成图像
device: torch.device,计算设备(CPU或GPU)
batch_size: 批大小
splits: 将生成的图片集分为几份计算IS
返回:
(is_mean, is_std): IS的均值和标准差
"""
# 加载预训练的Inception v3模型,用于分类
inception = models.inception_v3(pretrained=True, transform_input=True).to(device)
inception.eval()
preds = []
# 分批次计算预测概率分布
with torch.no_grad():
for i in range(0, len(images), batch_size):
batch = images[i:i+batch_size].to(device)
# Inception v3要求输入为299x299,如果 images 已经是此大小且已标准化则无需再次处理
logits = inception(batch)
probs = F.softmax(logits, dim=1)
preds.append(probs.cpu().numpy())
preds = np.concatenate(preds, axis=0) # (N, 1000)
# 计算IS
N = preds.shape[0]
split_scores = []
for k in range(splits):
part = preds[k * (N // splits) : (k+1) * (N // splits), :]
p_y = np.mean(part, axis=0)
scores = []
for i in range(part.shape[0]):
p_yx = part[i]
scores.append(np.sum(p_yx * (np.log(p_yx + 1e-10) - np.log(p_y + 1e-10))))
split_scores.append(np.exp(np.mean(scores)))
is_mean = np.mean(split_scores)
is_std = np.std(split_scores)
return is_mean, is_std
import os
from PIL import Image
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#######################
# 数据预处理Transform
#######################
# Inception v3预期输入尺寸为299x299,且通常使用标准化到[-1,1]
transform = transforms.Compose([
transforms.Resize((299, 299)),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
#######################
# 加载生成的图像 (fake_images)
#######################
def load_fake_images_from_folder(folder, transform):
images = []
for filename in os.listdir(folder):
if filename.lower().endswith(('png','jpg','jpeg')):
img_path = os.path.join(folder, filename)
img = Image.open(img_path).convert('RGB')
img = transform(img)
images.append(img)
# 将所有图像合并为一个Tensor: (N, C, H, W)
if len(images) > 0:
images = torch.stack(images, dim=0)
else:
images = torch.empty(0) # 如果没有图像则返回空tensor
return images
fake_folder = "/openbayes/home/miyan/works/Diffusion-Model-0-1/output/samples"
fake_images = load_fake_images_from_folder(fake_folder, transform) # (N,3,299,299)
is_mean, is_std = calculate_inception_score(fake_images, device)
print("IS:", is_mean, is_std)
FID评估
使用以下代码进行FID指标的测量:
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2):
"""
计算Fréchet Inception Distance所需的Fréchet距离。
参数:
mu1, sigma1: 实际数据特征均值和协方差矩阵
mu2, sigma2: 生成数据特征均值和协方差矩阵
返回:
fid: FID分数
"""
diff = mu1 - mu2
diff_sq = diff.dot(diff)
# 计算矩阵的对称矩阵平方根
covmean, _ = sqrtm(sigma1.dot(sigma2), disp=False)
if np.iscomplexobj(covmean):
covmean = covmean.real
fid = diff_sq + np.trace(sigma1 + sigma2 - 2 * covmean)
return fid
def calculate_fid(real_features, fake_features):
"""
计算 Frechet Inception Distance (FID)。
参数:
real_features: np.ndarray, shape (N, 2048),真实图像特征
fake_features: np.ndarray, shape (M, 2048),生成图像特征
返回:
fid: FID分数(越低越好)
"""
mu_real = np.mean(real_features, axis=0)
sigma_real = np.cov(real_features, rowvar=False)
mu_fake = np.mean(fake_features, axis=0)
sigma_fake = np.cov(fake_features, rowvar=False)
fid = calculate_frechet_distance(mu_real, sigma_real, mu_fake, sigma_fake)
return fid
transform_img = transforms.Compose([
transforms.Resize((299, 299)),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
dataset = load_dataset("huggan/smithsonian_butterflies_subset", split="train")
def transform(examples):
images = [transform_img(image.convert("RGB")) for image in examples["image"]]
return {"img": images}
dataset.set_transform(transform)
real_loader = DataLoader(dataset, batch_size=32, shuffle=False)
inception = models.inception_v3(pretrained=True, transform_input=True).to(device)
inception.eval()
# 计算FID需要real_features和fake_features(需要先提取特征)
# 可通过迭代real_loader对真实数据提取特征:
real_features_list = []
with torch.no_grad():
for batch in real_loader:
imgs = batch["img"]
imgs = imgs.to(device)
feats = inception(imgs)
real_features_list.append(feats.cpu().numpy())
real_features = np.concatenate(real_features_list, axis=0)
# 对 fake_images 同样提取特征
fake_features = []
with torch.no_grad():
for i in range(0, len(fake_images), 32):
batch = fake_images[i:i+32].to(device)
feats = inception(batch)
fake_features.append(feats.cpu().numpy())
fake_features = np.concatenate(fake_features, axis=0)
fid_score = calculate_fid(real_features, fake_features)
print("FID:", fid_score)
最终经测量得出的IS和FID指标如下:
| IS (mean ± std) | FID |
|---|---|
| 2.369±0.231 | 606.887 |
调整超参数以提升图像质量
超参数
扩散模型的超参数见训练配置:
class TrainingConfig:
image_size = 128
train_batch_size = 32
eval_batch_size = 8 # how many images to sample during evaluation
num_epochs = 100
gradient_accumulation_steps = 1
learning_rate = 1e-4
lr_warmup_steps = 1000
save_image_epochs = 10
save_model_epochs = 500
mixed_precision = "fp16" # `no` for float32, `fp16` for automatic mixed precision
output_dir = "output" # the model name locally and on the HF Hub
seed = 42
device = "cuda"
image_size:图像的分辨率,较小图像尺寸可以加快训练速度,但无法捕获复杂细节;较大图像尺寸能提升图像质量,但是会增加计算负担。train_batch_size:一次迭代中用于训练的样本数,较大的批量大小能提升模型稳定性,减少优化过程中的梯度震荡。eval_batch_size:评估阶段生成图像的数量,对训练过程没有影响。num_epochs:训练数据的完整训练轮数。gradient_accumulation_steps:梯度累计步数,增大此值能够实现更大的等效批量大小,从而提升训练的稳定性和图像质量。learning_rate:控制模型参数的更新步幅。lr_warmup_steps:在初始阶段逐步提升学习率,避免参数更新过快。
调整超参数重新训练
由于一次训练时间过长,尝试进行某些参数的调整以尽量提升图像质量。
将num_epochs提高到100轮,增加模型对于图像信息的学习轮数;将lr_warmup_steps提高至1000步,增加模型适应优化的过程,避免初期梯度下降不稳定的情况发生。
训练过程中每10个epoch验证一次,验证结果如下:
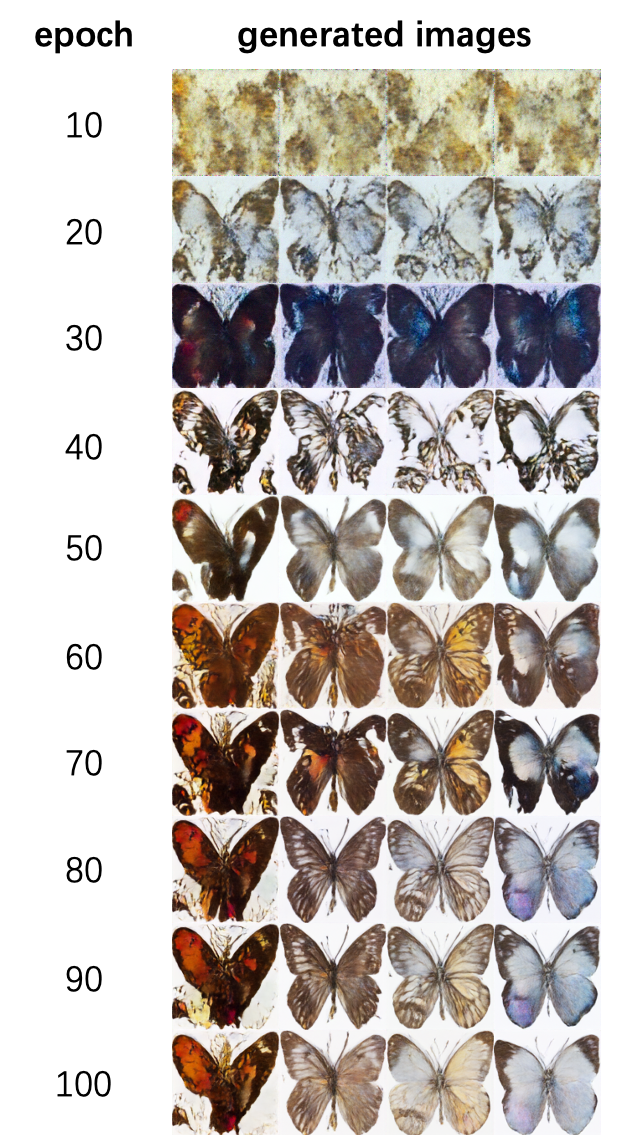
使用IS和FID指标进行评估
使用训练好的模型生成500张图像用于指标计算,指标以及指标提升对比如下:
| Model | IS↑ | FID↓ |
|---|---|---|
| Epochs 50 + lr warmup steps 500 | 2.369±0.231 | 606.887 |
| Epochs 100 + lr warmup steps 1000 | 2.237±0.217 | 380.933 |
IS值有所下降,这是由于训练图像过于单一导致图像多样性不足;FID值下降明显,说明生成图像与训练数据分布相似性提高,图像细节增加。
条件生成 Conditioned Generation
在使用带有条件信息(如文本描述)的图像训练生成模型时,通常会生成以类标签或者一段描述性文本为条件的样本。主要方法包括分类器引导的扩散 (Classifier Guided Diffusion) 和无分类器引导的扩散 (Classifier-Free Guidance)。
Classifier Guided Diffusion
无条件的噪声预测器使用以下公式进行噪声的预测和去噪过程:
分类器引导的扩散模型反向采样公式为:
Classifier-Free Guidance
- 条件噪声预测器$\epsilon_\theta(\mathbf{x}_t, t, y)$:基于目标条件 y 的噪声预测器。
- 无条件噪声预测器 $\epsilon_\theta(\mathbf{x}_t, t)$:不依赖任何条件的噪声预测器。
通过线性组合条件和无条件噪声预测器,可以构造出一种增强条件生成效果的噪声预测器:
在训练过程中,无条件和条件噪声预测器通过单个神经网络进行学习,其中条件信息$y$被定期丢弃,以便模型知道如何无条件的生成图像,即
潜在扩散模型 (Latent Diffusion Model)
潜在扩散模型通过在潜空间而不是像素空间运行扩散过程,从而降低训练成本并加快推理速度。模型发现的动机是观察到图像的大多数位置对感知细节都有着帮助,而且语义和概念信息经过压缩后依然存在。LDM通过使用自动编码器将信息编码到潜在空间,然后在潜在扩散过程中生成语义概念。
首先,给定高维数据$x_0$(如图像),通过一个预训练的自动编码器将其映射到潜在空间:

使用稳定扩散模型进行条件生成
训练参数
由于重新训练一个大规模的稳定扩散模型非常困难,因此使用图像-文本对数据集对预训练模型进行微调,来测试模型的生成效果。在stable-diffusion-v1-4的预训练权重上进行训练,采用lambdalabs/naruto-blip-captions(《火影忍者》中各个角色的图像-文本对)数据集进行训练。
训练参数的设置如下:
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export dataset_name="lambdalabs/naruto-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$dataset_name \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--checkpointing_steps=5000 \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--enable_xformers_memory_efficient_attention \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-naruto-model"
其中一些重要的参数有:
--pretrain_model_name_or_path:Hub上的模型名称或预训练模型的本地路径--dataset_name:Hub上的数据集名称或本地数据集路径--output_dir:训练模型的保存位置
设置Stable Diffusion的各种组成结构
由于需要使用文本作为条件进行生成,因此需要tokenizer和text encoder,将文本tokenize为一些tokens,再将tokens经过text encoder变为768维的embeddings。
tokenizer、noise_scheduler、text_encoder、vae和U-Net的导入如下:
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
# Load text encoder and vae
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
# Load U-Net
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
)
训练过程只调整U-Net的权重,冻结vae和text encoder的权重。
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
unet.train()
定义优化器用于优化U-Net的权重:
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
训练过程与DDPM部分流程一致,加入了将图像编码到潜在空间以及将文本tokens编码为embeddings的过程,其代码实现如下:
# Convert images to latent space
latents =vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"], return_dict=False)[0]
损失函数如下:
# Predict the noise residual and compute loss
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states, return_dict=False)[0]
# Loss
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
可以看到,噪声预测的过程中需要输入含有噪声的图像、时间步以及生成条件(文本编码的embeddings)。
完整代码位于Github仓库。使用bash train.sh启动训练。
训练与推理结果
在训练过程中加入Validation,可以看到在图像-文本对数据的训练下,生成图像的结果向着条件偏移,如下图中以Yoda和dog为prompt生成的图像。

训练完毕后,经过推理能够生成一些具有《火影忍者》画面特征的图像,如下图所示。

从推理结果中可以看出,U-Net经过Fine-tune之后,能够将预测噪声和去噪过程向着条件(《火影忍者》画面元素和画风)的方向进行引导,并且生成过程中受到文本信息的引导。
扩散模型个性化生成的微调方法
什么是个性化 (Personalization) ?
扩散模型(Diffusion Models)已在图像生成、文本生成等任务中展现出强大的性能。然而,实际应用中,不同用户或场景对生成内容的需求存在显著差异,当前通用生成模型往往难以满足个性化需求。因此,如何在保证基础模型通用性的同时,通过轻量化的微调方式快速适应个性化需求成为一个重要课题。
具体问题包括:
- 个性化数据的稀缺性:用户提供的个性化数据通常较少,直接训练可能导致过拟合或数据不足的问题。
- 计算成本:完全重新训练扩散模型需要大量计算资源,如何通过微调减少资源需求是关键。
- 生成质量:微调后的模型需平衡个性化特征和基础模型的生成能力,避免质量下降或生成内容单一。
DreamBooth
- 核心方法:基于特定用户的图像,微调扩散模型以生成包含指定个性化特征的输出。
- 特点:
- 使用极少量的个性化数据(例如几张带有某个对象的图片)。
- 通过在生成过程中添加一个特殊的标记("[V]")来关联用户提供的特征。
- 微调所有模型参数,同时保留模型对于通用任务的生成能力。
- 优点:适合生成高度一致的个性化内容。
- 局限:微调全参数模型,计算资源需求较高。

DreamTuner
- 核心方法:改进了DreamBooth的结构,增加主题编码器和主题自注意力来从粗到细地进行主题身份的保留。
- 特点:
- 仅需单张图像就可以进行个性化微调
- 可以与ControlNet相结合进行条件生成
- 优点:与DreamBooth相比,大幅降低了计算资源需求。
- 局限:模型结构较DreamBooth更为复杂。

Textual Inversion
- 核心方法:通过学习一个特定的文本嵌入(embedding),将个性化特征映射到模型的潜在空间。
- 特点:
- 不调整模型参数,而是学习一个新的特定Token,并将其与提供的个性化数据进行匹配。
- 生成时在文本提示(Prompt)中加入该Token,控制生成结果。
- 优点:
- 高效,无需对模型进行权重调整。
- 适合处理小规模的个性化需求。
- 局限:对输入特征的泛化能力有限,复杂需求可能难以满足。

Custom Diffusion
- 核心方法:局部参数微调技术,只微调扩散模型的U-Net中的参数。
- 特点:
- 通过局部参数更新,仅对生成特征高度相关的网络层进行调整。
- 提供更高的控制能力,用于生成特定风格或对象。
- 能够进行多个主题特征的个性化生成
- 优点:相比全参数微调,效率更高。
- 局限:更多概念的组合生成存在问题。

LoRA (Low-Rank Adaptation)
- 核心方法:在模型的权重矩阵中引入低秩分解,并只训练新增的低秩矩阵。
- 特点:
- 保持原模型的权重冻结,减少训练参数规模。
- 通过添加低秩调整项,提高模型对个性化需求的适应性。
- 优点:
- 极大降低训练成本和显存需求。
- 易于与预训练模型兼容。
- 局限:对高度复杂的个性化生成需求支持可能不足。
IP Adapter
- 核心方法:使用具有解耦交叉注意力机制的适配模块,将图像特征嵌入预训练扩散模型中。
- 特点:
- 模块化设计,在不改变主干模型的基础上实现个性化生成。
- 适配器模块的参数规模小、训练开销低。
- 优点:可推广至其他自定义模型以及结构控制模型。
- 局限:适配器设计的复杂性可能影响最终生成质量。

总结
扩散模型作为生成模型的一种,通过正向和反向的扩散过程,实现了噪声预测和去噪,进而实现了从噪声中生成图像的功能。条件扩散模型通过将条件信息加入噪声预测器中,使得去噪过程能够在条件引导下进行。潜在扩散模型通过将信息编码到潜在空间以及在U-Net中加入交叉注意力机制,实现了模态的对齐以及更加高效的扩散性能。
Citation
文章部分内容来自
Weng, Lilian. (Jul 2021). What are diffusion models? Lil’Log. https://lilianweng.github.io/posts/2021-07-11-diffusion-models/.
文章代码开源在